標本調査とは?
標本調査とは?
全数調査と標本調査
-
全数調査とは
統計調査によって何かを調べたい時、例えばある中学校で全校生徒の平均身長を調べたいと思ったら、生徒全員の身長を測って平均を計算すれば正確な結果が得られます。このように、対象となるすべてを調べる調査を「全数調査」といいます。一つの中学校の全生徒の身長を調べることは、それほど大変な手間ではないでしょうが、日本中のすべての中学生の身長を調べるのは大変な手間と費用がかかります。このような場合には、手間や費用を省くために、一部の人だけを選んで調べる方法もあります。このような調査を「標本調査」といいます。
全数調査は、集団の中をすべて調査しますので、集計した結果には、標本調査では必ず生ずる「標本誤差」が含まれません。したがって、全体の結果はもちろんのこと、男女別の結果や詳細な地域別の結果なども統計として利用できます。
我が国で実施されている最も大規模な全数調査は国勢調査ですが、国勢調査では、全国結果だけでなく、都道府県別、市町村別はもちろん、町丁・字などの小地域の結果や、男女別・年齢別などの詳細な結果も公表されています。
-
何のために全数調査が必要なのでしょうか?
全数調査の結果には、上述のように標本誤差が含まれませんので、例えば国勢調査の結果は、衆議院議員の小選挙区の画定基準や地方議会の議員定数の決定、地方交付税の算定基準など、「法定人口」としてさまざまな場面で利用されます。
また、全数調査は、統計体系の中で、定期的に他の統計の基準となる数値を提供するという、統計の正確性を担保する根源となっています。具体的には、例えば5年ごとに行われる国勢調査から作られる統計は、日本の現在人口と将来人口の推計の基礎とされており、国勢調査の結果が得られるごとに、これらの推計の基礎が見直されています。このような基準とされる数値のことを、「ベンチマーク」と呼んでいます。また、国民経済計算
 などの加工統計(統計調査の結果だけでなく、さまざまなデータを集めて加工して作成する統計)でも、推計の基準とされる人口は国勢調査を基にしていることから、同様に国勢調査の結果が得られるごとに改定が行われます。
などの加工統計(統計調査の結果だけでなく、さまざまなデータを集めて加工して作成する統計)でも、推計の基準とされる人口は国勢調査を基にしていることから、同様に国勢調査の結果が得られるごとに改定が行われます。もう一つの重要な役割は、標本調査を設計する際の基礎としての役割です。
標本調査は、ある集団の中から一部の対象だけを抽出して調査するもので、我が国で行われている統計調査の多くはこの方法により行われています。標本調査により正確な統計を作るためには、調査対象とする集団全体の数や性質がわかっていないといけません。したがって、標本調査の企画・設計の段階で、その集団に含まれる対象すべてを含んだリストが必要になります。
例えば、経済関係の統計調査では、多くの場合、全国の事業所・企業の中から一部のものを抜き出して調べます。その場合に必要となる事業所・企業のリストは、多くの場合、全数調査である 事業所・企業統計調査(平成21年からは経済センサス)によって整備されたリストが用いられます。つまり、全数調査は、他の多くの標本調査を実施するために必要不可欠な情報を与えるものとしても活用されています。
このように、全数調査は、その統計自体にも重要な役割がありますが、他の統計調査を行うための基礎にもなっており、統計調査の体系の中で中心的な役割を果たしているのです。
-
何のために標本調査が必要なのでしょうか?
しかし、すべての統計調査で対象者全員を調査した場合、膨大な費用と手間がかかります。身近な例の中から、テレビ番組の視聴率を例に挙げてみましょう。テレビや新聞などで、「昨年末の紅白歌合戦の視聴率は○○%だった」とか「先週1週間で最も視聴率が高かった番組は○○○だった」などの報道を目にしますが、皆さんの中に視聴率の調査を受けたことのある方はほとんどいないと思います。視聴率は、対象となる地域(例えば関東地方)の全世帯を対象に調査すると莫大な経費を必要としますし、結果をすぐに(例えば次の日などに)出すことができませんので、このような場合、一部の世帯だけを統計的に偏りがないように選んで調査をします。これを「標本調査」といい、選ばれた調査対象を「標本」(サンプル)といいます。
標本調査は、選ばれた一部の標本を対象に調査を行い、すべての対象を調べるわけではありませんので、その結果には誤差(これを「標本誤差」といいます)が含まれますが、標本の選び方を工夫すれば、誤差をあまり大きくすることなく、調査にかかる費用と期間を大幅に縮減することができます。したがって、多くの場合、統計調査は標本調査により行われています。
総務省統計局が実施している、例えば労働力調査や家計調査、社会生活基本調査やサービス産業動向調査などのほとんどの統計調査は、標本調査により行われています。
標本調査
-
標本調査を行う前に
標本調査は、ある集団の中から一部の調査対象を選び出して調べ、その情報を基に、元の集団全体の状態を推計するものです。調査の対象とされている「元の集団全体」のことを「母集団」と呼びます。
標本調査の目的は、標本を用いて母集団の状況をできるだけ正確に復元推計することです。正確な推計結果を得るためには、標本が母集団全体の特徴をよく表したものになるように、つまり、母集団のよい縮図となるように抽出することが大変重要です。
-
有意抽出法と無作為抽出法
標本の選び出し方には、「有意抽出法」と「無作為抽出法」とがあります。
有意抽出法は、「代表的」あるいは「典型的」と考えられる調査対象を抽出する方法です。この方法によれば、調査の企画者が様々な情報を基に、よく考えて調査対象を抽出すれば、母集団のよい縮図となる標本を選べるのではないか、と思われるかも知れません。しかし、実際には、この方法は主観的な判断に頼ることになり、この方法によって集団全体を代表する標本を選ぶことは極めて困難です。有意抽出法の大きな問題は、選ばれた標本が母集団のどのような部分を代表しているのか、統計的に評価ができないことです。
これに対して無作為抽出法は、調査の企画者の主観的判断を排除して、標本をくじ引きのような方法で、無作為に抽出する方法です。くじ引きのような確率的な出来事に関しては、確率論など統計数理の理論を当てはめて、標本から全体の数値を推計したり、推計結果の誤差を評価したりすることができます。無作為抽出によってある程度多数の標本を集めると、推計結果は安定し、精度の高い推計結果が得られます。
-
無作為抽出の手順
無作為抽出を行うには、実際にどのようにやればいいのでしょう。
「無作為」という言葉から、単に「でたらめ」に選べばいい、と考えられがちですが、本当の意味で無作為に選ぶためには、きちんとした手順を踏む必要があります。
無作為抽出の方法として最も典型的なものは、次のとおりです。
まず、母集団を構成する全員のリストを用意します。このような母集団全員を含むリストは、「標本フレーム」または「標本枠」と呼ばれることがあります。
次に、リストに含まれる全員に一連の通し番号を付けます。そして、その中から、乱数表などによって得た乱数に従って、調査対象を選び出します。
こうして得られた調査対象を調査すれば、無作為抽出による標本調査となります。
-
「無作為抽出」=「でたらめ」ではない
では、単に「でたらめ」に調査対象を選んだ場合には、どんな問題があるのでしょうか。
ここで一つの事例を考えてみましょう。ある町で、住民を対象に標本調査を行うとします。「でたらめ」に調査対象を選ぶために、簡単な方法として、その町の一番大きな駅の前に立って、通行する人に誰でもかまわず無作為に(でたらめに)声をかけて、調査してみたとしましょう。
この方法は、無作為抽出法となっているでしょうか。
この方法は、次のような理由から、これは無作為抽出法となりません。
駅前を歩いている人は、町の住民すべてを代表しているとは限りません。住民の中には、その駅を使わない人もいるでしょう。また、調査をしている時間帯に、住民すべてが駅前を歩いているわけではないので、ほかの時間帯にしか出歩かない人は調査されません。さらに、忙しい人は、呼びかけても立ち止まって調査に協力してくれないかも知れませんので、立ち止まって協力してくれる人は、時間に余裕のある人だけかも知れません。
つまり、この方法で調査に回答してくれる人たちは、その町の住民全体の中から選ばれたというよりは、むしろ、その町の住民のうちで、その駅を利用する人で、かつ、調査の時間帯に駅前を歩いていて、さらに、立ち止まって答えてくれた人、ということになります。したがって、調査に協力してくれる人は、町の住民の中でも、上述のような特定の特徴を持った人たちと考えられます。そのような人たちが、その町の実態を反映した縮図になっているとは言えません。
したがって、このような方法で統計調査を行っても、その結果が何を意味するのか、わからないものとなってしまいます。
-
集落抽出法
母集団を構成する全員のリストがあれば上述のような標本抽出が可能ですが、多くの場合、このようなリストは存在しません。すべての調査単位を含むリストが利用できない場合、どのようにして標本の抽出を行えばいいのでしょうか。
このような場合に用いられる代表的な方法として、「集落抽出法」と呼ばれる方法があります。これは、個々の調査単位を直接選ぶのではなく、まず調査を行う地域を選び、次に、その地域の中に含まれる調査単位をすべて調べる方法です。例えば、世帯を対象とした標本調査を行う場合、全国の全世帯のリストは存在しませんので、国勢調査の調査区の中から、調査の対象とする調査区を一定数、無作為抽出法により選び出し、その調査区の中のすべての世帯を調査するのです。
このように、調査対象を地域のまとまり(集落)ごとに抽出することから、「集落抽出法」と呼ばれています。
この集落抽出法では、国勢調査の調査区のように、調査の対象となる地域をもれなく重複なくカバーしている、区画の明確な地域の単位を用いることが必要です。国勢調査の調査区は、平均的に約50世帯が含まれるように日本全国を区画して作られ、全国に約90万の調査区が設定されています。各調査区に関しては、調査区地図が整備され、境界が明確になっていますし、国勢調査の結果によって、各調査区の特性に関する統計が整備されていますので、国勢調査の調査区は、集落抽出法における抽出の対象として用いられることがしばしばあります。
-
二段抽出法
母集団に含まれるすべての単位のリストが利用できない場合に、集落抽出法以外でよく用いられているのが「二段抽出法」です。
二段抽出法は、最初に調査地域を無作為に抽出するところまでは集落抽出法と同じですが、その先が異なります。調査地域内をすべて調べるのではなく、その地域の中から一部を無作為に選び出して調査するものです。この場合、すべての調査対象のリストが存在しなくても、選ばれた調査地域内の調査対象のリストさえ作れば、標本を抽出することができます。
このように、一段目では調査地域を選び出し、さらに二段目では世帯などの調査対象を選び出すという2段階の方法で標本を選ぶので、「二段抽出法」と呼ばれます。(同様に「三段抽出法」などもあり、これらを総称して「多段抽出法」と呼ぶこともあります。)
同じ地域に特徴の似ている世帯が集まっている場合には、調査区内のすべての世帯を調べる代わりに、その中の一部の世帯を抽出して調査しても、それほど調査結果の精度は低下しません。このため、二段抽出法によれば、1地域にかける調査費用を節約することができ、そうして節約された経費を活用して、調査地域の数を増やして全国に広く散らばらせることができるので、同じ費用で調査結果の精度を向上させることが可能です。
-
標本抽出の具体例
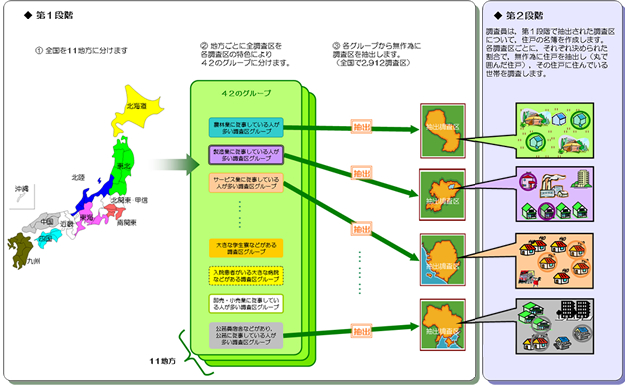
以上で説明した標本抽出の具体例を、総務省統計局が実施している労働力調査を例にとって解説します。
労働力調査では、下図のように、一段目に国勢調査の調査区を、二段目に調査区内にある住戸を抽出する二段抽出法によって標本を抽出しています。
標本誤差
-
標本誤差と非標本誤差
統計調査の結果には、必ず何らかの誤差が生ずることは避けられません。例えば、標本調査では、調査されなかった調査対象がありますので、全数調査を行えば得られたはずの値(これを仮に「真の値」と呼ぶことにします)と調査結果には差が生じます。また、全数調査を行ったとしても、回答者が回答誤りをしたり、回答をしなかったりすることにより生ずる誤差もあります。このうち、全数調査を行わずに標本調査を行ったことにより生ずる差のことを「標本誤差」といい、それ以外の、例えば誤回答や未回答による誤差を「非標本誤差」といいます。
非標本誤差には、上述の誤回答や未回答によるもののほか、標本が正しく母集団の縮図となっていなかったことによる誤差、集計の際の誤りによる誤差など、いろいろな要因によるものがありますが、このような誤差は、どの程度の誤差が発生しているのか、数字で評価することができません。したがって、調査の設計の際には細心の注意を払ってなるべく起こらないようにすべきです。例えば回答者の回答誤りについては、誤解が生じにくいように調査票を設計するなどの工夫が必要です。
一方、標本誤差は、標本調査には必ず存在する誤差ですが、その誤差の大きさを数学的に評価することが可能です。詳しくは次項以降で解説します。
-
標本誤差とは?
標本調査では、調査対象を無作為に抽出して調査をしますので、どの対象が選ばれるかは偶然によって左右されます。このため、標本調査の結果は必ずしも母集団の値、すなわち真の値とは一致せず、何らかの差があります。このように調査対象の一部を選定することによって起こる、真の値と調査結果との差を「標本誤差」といいます。
標本調査を行うときは、この標本誤差の存在を忘れてはなりません。標本誤差がどのくらいになるかを予測した上で標本の大きさ(標本に含まれる調査対象の数)などを決定する必要があります。
また、標本調査を行う場合だけでなく、調査結果を見る際にも標本誤差の存在を忘れてはなりません。調査結果を見る人に統計を正しく利用してもらうためにも、標本誤差を測っておく必要があります。
-
標本誤差を測るには?
標本誤差を測るときには、次のことに注意する必要があります。
一つは、標本調査を行うときには、普通、真の値は分からないということです。(この値が分かっていれば、標本調査をする必要がありません!)このため、真の値が得られていることを前提にして標本誤差を測ることはできません。したがって、標本誤差(真の値と調査結果との差)を直接的に測ることは困難であり、現実には、一定の理論式に基づいて標本誤差の大きさを推定する方法が一般的です。
また、標本誤差は抽出された標本ごとに異なります。もし、同じような標本調査を何度か繰り返して行ったとすれば、調査のたびごとに異なる対象が選ばれ、そのたびに調査結果は変動します。そこで、標本誤差を表すには、仮に同じ標本調査を何回も繰り返し行ったとした場合、真の値との差が確率的にどの程度ばらつくか、そのばらつき具合を示す数値が用いられます。
したがって、標本誤差は、確率的なばらつきの幅を示す尺度で表されます。
標本誤差は、調査結果を見る際に、どの程度確かな数字であるかを判断するための情報で、例えば「この調査結果と真の値との差は95%の確からしさで○○円以内である」などと表されます。
なお、標本誤差とはこのような性質のものですので、推定結果に何かの数値を足したり引いたりして、修正できるようなものではありません。このため、もしも誰かに、「標本誤差があるならば、その誤差を修正した値を出してもらえないか」と頼まれても、修正することはできません。
-
どのくらいの標本を調べればいいのですか?
先に述べたように、標本調査を行うときには、どのくらいの標本誤差が見込まれるかを予測し、それを踏まえて標本の大きさを決めて調査を設計する必要があります。
まずは簡単な例で、10,000世帯が住んでいる町でパソコンの普及率を標本調査により調べる例を考えてみましょう。詳しい説明は省略しますが、この場合、標本誤差は、95%の確率で以下の値以下になります。
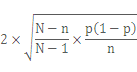 (ただし、Nは母集団の大きさ、nは標本に含まれる調査対象数、pはパソコンの普及率)
(ただし、Nは母集団の大きさ、nは標本に含まれる調査対象数、pはパソコンの普及率)この数式のうち、
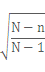 の部分は、母集団の大きさに対する標本の大きさの割合(これを「抽出率」といいます)が小さい場合は1に近くなります。
の部分は、母集団の大きさに対する標本の大きさの割合(これを「抽出率」といいます)が小さい場合は1に近くなります。例えば、10,000世帯から100世帯を選んで調査をする場合、
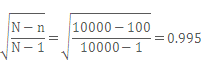 となり、ほとんど1に等しいと言えます。
となり、ほとんど1に等しいと言えます。したがって、そのような場合は、上の式は、
 と簡略化することができます。
と簡略化することができます。この数式は、p=0.5のとき、すなわちこの町のパソコンの普及率が50%だった場合に最大値をとり、
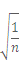 となりますので、仮に100世帯を調査対象とした場合、「調査結果と真の値との差は95%の確率で0.1以内にある」と予測できることになります。パソコンの普及率が50%という調査結果が得られた場合、真の値は95%の確率で40%〜60%の間にある、ということになります。
となりますので、仮に100世帯を調査対象とした場合、「調査結果と真の値との差は95%の確率で0.1以内にある」と予測できることになります。パソコンの普及率が50%という調査結果が得られた場合、真の値は95%の確率で40%〜60%の間にある、ということになります。したがって、調査結果に求める精度がこのくらいでよければ、標本となる世帯を100世帯選んで調査すればよい、ということになりますし、もっと高い精度を求めるのであれば、調査する世帯数を増やす必要があります。
ここで注目していただきたいのは、上の簡略化した式は母集団の大きさには関係しない、ということです。つまり、1万世帯の町であっても、100万世帯の大都市であっても、100世帯を調べた時の標本誤差は同じになる、ということです。
一方、抽出率が高い場合(例えば40人のクラスから20人を選んで調査をしようとした場合など)には、
 部分を省略することはできませんので、注意が必要です。
部分を省略することはできませんので、注意が必要です。参考までに、上のような例の場合の標本の大きさと標本誤差の関係を以下に示します。
例1 抽出率が低い(注1)場合 標本の大きさ 調査結果が50%だった場合(注2)に真の値が95%の確率で存在する範囲 100 50.0%±10.0、すなわち40.0%〜60.0% 200 50.0%±7.1、すなわち42.9%〜57.1% 500 50.0%±4.5、すなわち45.5%〜54.5% 1000 50.0%±3.2、すなわち46.8%〜53.2% 2000 50.0%±2.2、すなわち47.8%〜52.2% 3000 50.0%±1.8、すなわち48.2%〜51.8% (注1)
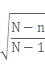 =1と見なしても差し支えない場合。
=1と見なしても差し支えない場合。(注2)調査結果が50%ではなかった場合、この幅は上例よりも小さくなります。
例2 抽出率が高い(注1)場合 母集団の大きさ 標本の大きさ 調査結果が50%だった場合(注2)に真の値が95%の確率で存在する範囲 200 100 50.0%±7.1、すなわち42.9%〜57.1% 200 50 50.0%±12.3、すなわち37.7%〜62.3% 100 50 50.0%±10.1、すなわち39.9%〜60.1% 100 25 50.0%±17.4、すなわち32.6%〜67.4% 40 20 50.0%±16.0、すなわち34.0%〜66.0% 40 10 50.0%±27.7、すなわち22.3%〜77.7% (注1)
=1と見なすことができない場合。(注2)調査結果が50%ではなかった場合、この幅は上例よりも小さくなります。
